
Holidays are in full swing, and we are all trying to immortalize more or less aesthetic happiness, from the landscape, from the children in the water, from the seductive regional specialty … With a simple nod, the camera is unwrapped, flipped over and the photo taken. From this moment on, a whole world of algorithms starts working and it will make that at the end of the process, you will get a picture that you will eventually share. What are these algorithms? What are their roles? How do they work? For the answer, let’s follow the image step by step through the twists and turns of its journey. It all starts with the acquisition of the image…
Just as our eyes have a retina that receives rays of light reflected by an object, any camera is equipped with a sensor, which is the equivalent of film in film photography. This electronic component is made up of millions of phototypes, types of sensitive “cells” that react to the amount of light they collect and convert it into an integer recorded in the device’s memory. Thus, the sensor converts the image into a table of values, or matrix, each square of which is delimited by horizontal coordinates x And another vertical therecorresponds to a pixel (for picture element, i.e. “image element”), one for each Photoshop site. The higher their number, the higher the definition of the image.
The camera also records information (we are talking about “metadata”), such as the camera model, lens, date, time, location… This information added to the sensor’s raw data makes up a RAW file. At this point, the image is just a set of intensity values, from darkest to brightest. In other words, the image initially obtained by an exposed sensor is all shades of gray.
50 shades of gray and more
It will then be processed by several algorithms to produce the final, almost “perfect” image, the one that will give the illusion of reality, and stored. Most often, at least for beginners, everything happens in the device, thanks to the various built-in programs, the implementation of which sometimes depends on the metadata that accompanies the image.
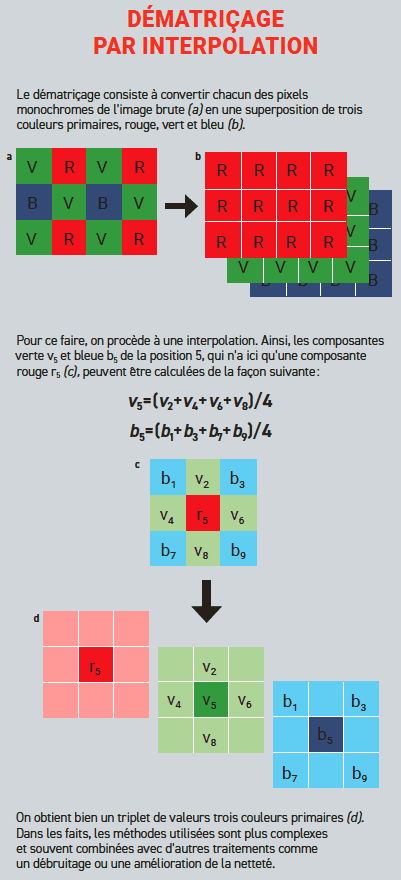
The first step is to convert the image in shades of gray to a colored one. The technology used is inspired by human perception, by associating each of the matrix values with one of the three primary colors, red, green or blue. To do this, the entire sensor is covered with a filter, which is a kind of mosaic of colored elements (one for each optical site) in which there are different arrangements, the most common of which is the Bayer matrix, consisting of 50% green, 25% red and 25% blue (see fig. below). The predominance of green in this tiling is due to the fact that human vision is more sensitive to it. In this way, each optical site detects only the intensity of the associated primary color. Thus, each pixel of the raw image contains only one component, red, green or blue.

The Bayer Matrix consists of a filter,
Sensor-mounted color mosaic.
Each pixel of the latter is superimposed
monochromatic element.
The goal is to get triplets of each of these monochromatic pixels (sAnd the FifthAnd the B) from the values of the three primary colors, respectively. To do this, the program goes into effect to perform a demosaicing process during which the chromatic data of each of the monochromatic pixels is interpolated with that of the neighbors so as to estimate the two missing components. all value sAnd the Fifth And the B obtained is an 8-bit encoded computer, and thus is between 0 and 255 (28 = 256). At the end of this process, the color image finally consists of three overlapping matrices or channels: one with the values representing red, one for green and the last for blue.
According to the theory of additive composition, which also operates in television and computer screens, the variation in the intensity of light associated with each channel provides access to all colors of the visible spectrum. Thus, the triple value (96, 93, 62) corresponds to the color khaki green. We’re close to a render-ready image, but there’s still some processing to be done.
On the way to the masterpiece
The image sometimes requires color calibration, for example for color casting to soften, as well as white balance to get an accurate color image of the scene regardless of the lighting conditions. Other treatments are traditionally integrated into the series: this may include exposure correction or lens optical compensation. In the latter case, the software often includes a database of lenses to overcome optical distortions and chromatic aberration, which leads to the presence of unwanted colored fringes around the elements of the image.
This is not all. This is followed by gamma correction, which makes the scene brightness more consistent with that perceived by human vision, and other operations that improve sharpness, reduce the “grain” effect (we are talking about “noise reduction”), remove blurring, improve contrast and remove small local defects.. Until you get the desired and satisfying image for everyone, or at least for its author. It is clear that he wants to preserve his “masterpiece”. Then the question of storage arises.
It’s about storing all the information about the image (the set of ternary color values and Exif data) in memory, but there are several ways to do this. Viewing the image then consists of ‘undoing’ this storage: an image cannot be ‘seen’ ‘ordered’, like an image folded and put away in an envelope that must be taken out and exposed in order to be viewed.! To achieve this, the renderer must know your storage method, which is called format, and one of the most common is Tiff (for Mark (C) image file format).
Better organization to save space
However, such a format is large and can easily reach several tens of megabytes (MB). A smartphone with 16GB of memory gets saturated quickly. To address this, we prefer to compress files, i.e. store them in such a way as to reduce the space occupied on the digital medium. For photos, the compression standard is JPEG (for Joint Photographic Experts Group).
The JPEG algorithm is based on the quality parameter Q, the values of which range from 1 to 100: the smaller it is, the more the image loses its quality (see the figure on the opposite page). In fact, stress leads to a loss of information, especially those related to details not visible to the human eye. How does pressure work?
First, the RGB image is converted to another base called YCbCr, consisting, on the one hand, of the observed luminance channel Y (a quantity corresponding to the visual sense of brightness, in fact the image is in gray) and on the other hand, the hand, two color (or two) channels denoting Cb and Cr. The benefit of this new color space is the décor relationship between luster information and color information. The eye is now more sensitive to the first than to the second. Thus, image compression consists in weakening the chromaticity while maintaining good quality. More precisely, fewer color channels are sampled to occupy less space: the idea here is to standardize the chromaticity of neighboring pixels, say 4 aligned, without taking into account the luminance.
During the next step, each of the three channels is sliced into blocks of 8 x 8 pixels which undergo a mathematical treatment, in this case a variant of the Fourier transform, which converts it into a sum of cosine functions characterized by its frequency. This is important, because low frequencies generally correspond to the image, as if we saw it blurred, while high frequencies represent details, what differs, features … It is at very high frequencies, referring to elements of the image in which the human eye is very insensitive So much so that the pressure will basically bear it.
This consists of a quantification (the continuous signal is replaced by discrete small group values, which reduces the amount of information) depending on the parameter Q mentioned above. Quantization is the irreversible step in the algorithm during which most information loss occurs. Then each block is encrypted using other types of algorithms, without data loss.

The quality and size of a compressed JPEG image varies according to a Q-factor between 1 and 100.
© T. nqqhh
The life story of the photo does not end there. Apps like Instagram, Facebook or Snapchat offer to crop and straighten the photo and apply different filters to it. All these actions are also based on image processing algorithms. When posting to social networks, they also apply transitions: they can resize images, compress them again and, most often, remove Exif metadata. On a larger scale, many other operations are carried out, but they are kept confidential by companies, as is the order in which they are applied.
All of the methods mentioned here, and many others, are important research topics that continue to be of interest. New procedures are constantly being developed in response to the arrival of new technologies, the desire for better quality images, and the sharing possibilities offered by the Internet.
Algorithms for all
More broadly, every field in which images are central, such as medicine, astronomy, satellite observation, etc., has its own set of algorithms for image formation, optimization, display, and coding. Other tools help analyze images to extract information, such as detecting objects or motions.
Scientists studying these different topics publish articles, some of which are available online, on the image processing reference journal website: IPOL (for Online image processing). This post has the advantage of offering to read the description of the method, but also download the computer software provided, and even test each of the methods with their own pictures directly Across Location. So it’s up to you to play with your holiday photos!


“Subtly charming problem solver. Extreme tv enthusiast. Web scholar. Evil beer expert. Music nerd. Food junkie.”